A Casual Analysis of Dreambooth and Fine-tuning Diffusion Models
Published on: 11-30-2024
An exploration of how Dreambooth leverages CLIP encoders for efficient fine-tuning of diffusion models.
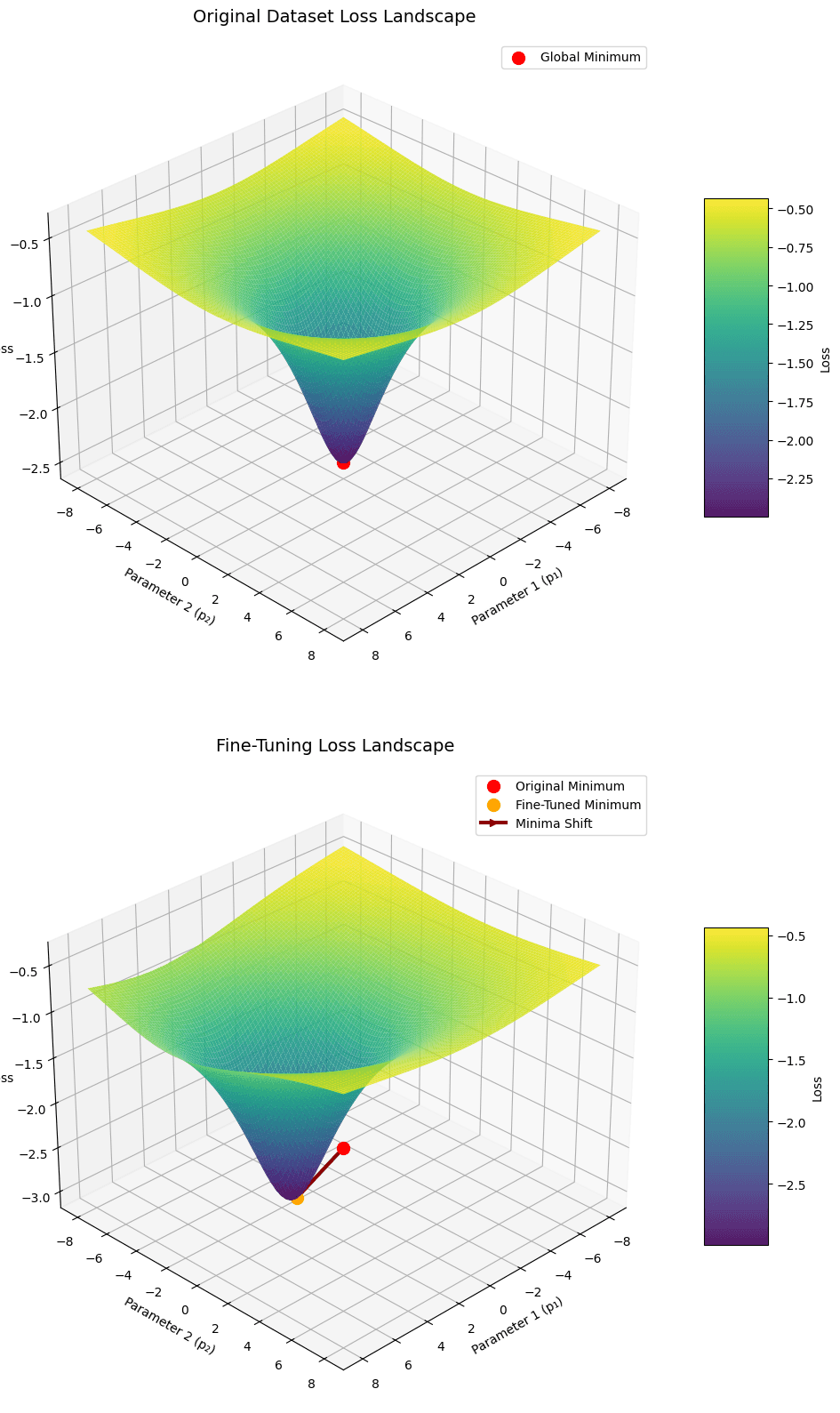
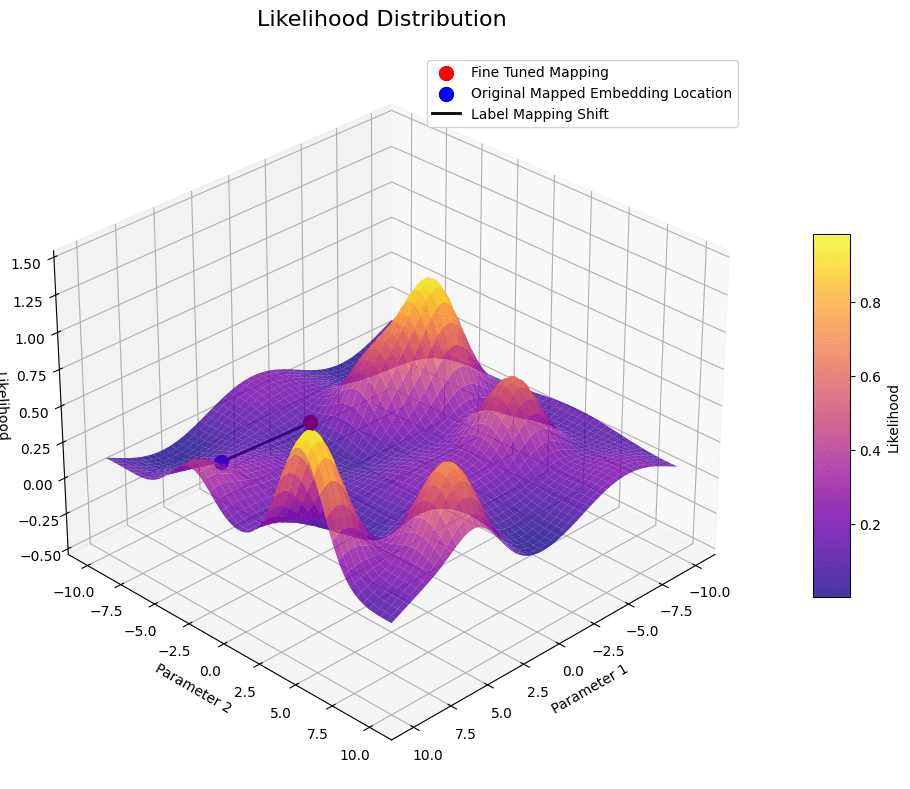
Published on: 11-30-2024
An exploration of how Dreambooth leverages CLIP encoders for efficient fine-tuning of diffusion models.